
Development of audio classification software for the radio programmes of the Cultural Broadcasting Archive.
Our objective is to develop a solution for the automatic music-versus-speech annotation of the 17,000-plus radio programmes in the CBA online archive. The literature shows that promising approaches to such a task already exist. These are mostly based on established machine learning approaches using, for example, SVM classification, and with features such as MFCC. Seyrlehner et al. present continuous frequency activation (CFA), which integrates feature and classification, and outputs a single numerical value for each chunk of audio.
The CBA mainly consists of audio from community radio stations. In contrast to the archives of professional broadcasters, the audio quality in the CBA varies greatly due to differences in equipment quality and audio engineering expertise. Our challenge is to create a method of classification which can cope with this variation in quality. We assume we will be able to develop a solution by combining a range of features and various pre- and post-processing steps.
Project Website
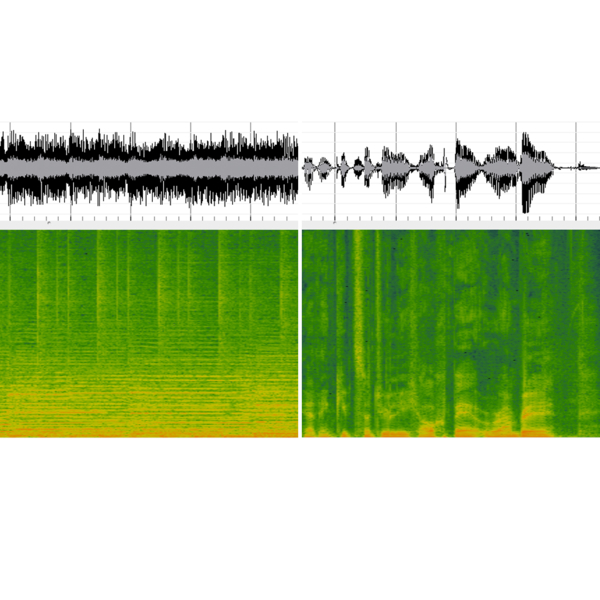
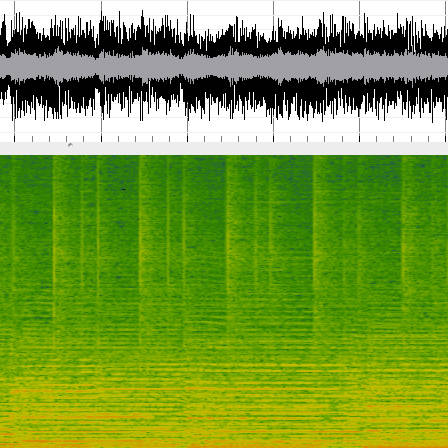
Music compared to speech
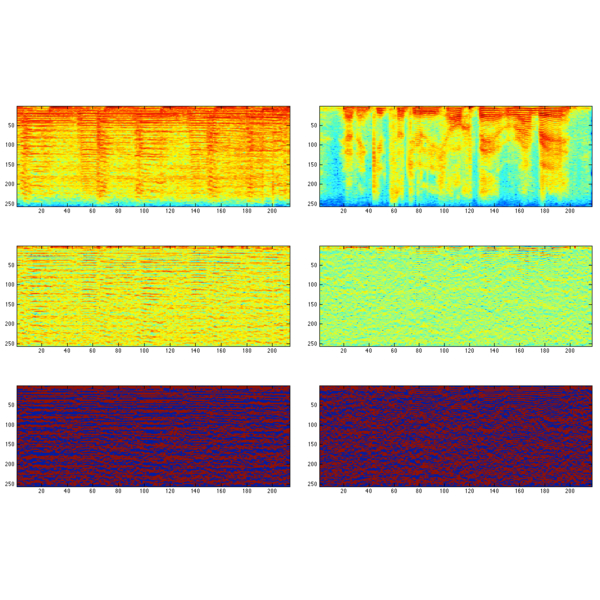
Binarization step of the Continuous Frequency Activation feature
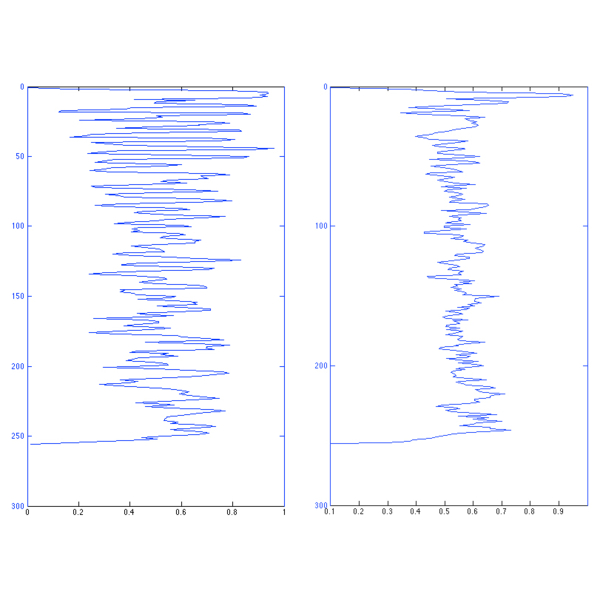
Sum of the binarized signal. Music leads to spikier peaks
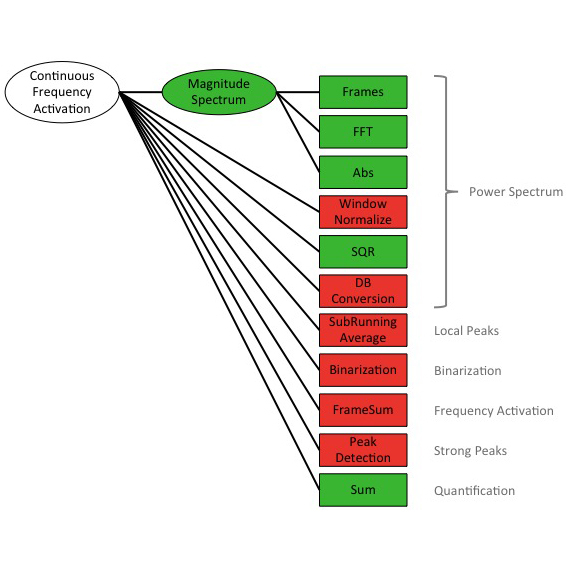
Computation steps of the CBA-Feature